The research in the area of Machine learning and Data science is exploding, both in academia and in the industry. In 2020, 54,160 papers were submitted to arxiv cs alone, with roughly fifth of them submitted to cs.LG, a sub-archive focusing on Machine Learning (1).
This flood of information and research is exciting. New discoveries are made, pushing science forward, but also impacting the industry.
At the same time, it can also be frustrating. One can feel, rightfully so, overwhelmed by the amount of papers, methods and tools. It can be really hard to navigate your way through all of the available information, especially when this has to be done alongside your daily tasks as an employee in the industry.
The industry today goes hand to hand with academia, often lagging only slightly and occasionally even being the front runner. The appetite for cutting edge solutions and models from customers requires even the most production-oriented teams to be “on top of things”.
While some solutions to keep up with research exist, none of them is convenient, systematic and covers all bases. Using arxiv RSS alone creates endless emails, most of which will most likely not be read. Using recommendation systems of some of the reference managing tools lacks personalization and flexibility. Finally, using social media such as reddit or twitter can be overwhelming and time consuming on it’s own.
Facing the same challenges in our team, we devised a system that helps us to stay on top of things while requiring very little effort on our part after completing the primary installation.
Our approach consists of two main parts, sources of information and channels to deliver it.
1. Sources – one can think of multiple websites, research databases, publications, blogs etc.. that can provide valuable information. However, decisions had to be made in order to refine the search. We decided to focus on relevant sub-archives of arxiv, Towards data science, twitter and Connected Papers. I will discuss each of them and the value they provide later on.
2. Communication channels – as a company we work with slack, so it made a lot of sense to use it as a delivery mechanism. Moreover, for most people, the other solutions in the form of emails or active browsing are time consuming and inconvenient, making them more likely to default. Slack offers an option to use webhooks to post messages on different channels. Most of the sources we used provide rss feeds. We wrote a simple python code that parses the rss feed, filters it if needed and posts it to the channel using the webhook. More on that below.
Diving deep into each solution with steps and code
Watching for papers on arxiv and Towards data science
The general scheme is as follows: Each of the sub-archives in arxiv provides an url for it’s daily rss feed. This url is used by our python code that is heavily based on PaperWatchDog tool (2) to parse the feed, filter it if required and style it as we want it to appear on the slack channel. Then, using a slackweb api package and a webhook app that we established in advance we post the messages onto the selected slack channel. To perform this on a daily (or other) basis, we use crontab as a job scheduler.
I will explain in details each of the steps:
- Setup a webhook for your slack channel
- Create a slack app, use the instructions here: https://api.slack.com/messaging/webhooks to create a basic app on one of your workspaces and name it as you wish.
- Follow the same instructions and enable incoming webhooks.
- Now, you can add webhooks to specific channels. Create a new channel or use an existing channel.
On slack, click on the channel name > integrations > add an app > choose the app you have just created.
Then, go back to your app screen on the dashboard > Incoming webhooks > scroll down and press “Add New Webhook to Workspace”. Choose the channel and press allow. This will add a new line to your webhook URL list. You will use these urls later on for posting.
- Clone our github repository locally
‘git clone https://github.com/dinaber/KeepingUpWithResearch.git’ - Create a conda environment with the requirements
Using the requirements file provided in the github repository
`conda create –name python=x.x –file ` - Create a watch list based yml file
Basically this file will indicate which rss feeds you want the tool to scan on each plan. Meaning, for different plans create different watch lists. For example, for my daily 9AM scan I am looking at the arxiv.ML and Towards data science. For my twice a week scan I am looking at arxiv.LG and each of these is a plan that requires a separate watch list.
Let’s look at the example provided in our github (KeepingUpWithResearch/daily_watch/PaperWatchDog/files/explainability_watch_list.yml) repository to understand what should be included in this yml: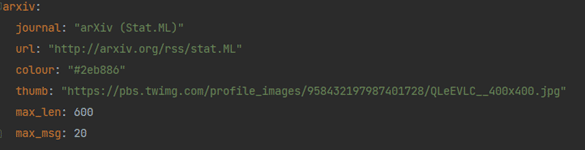
- journal – the name of the journal as you want it to appear on slack
- url- the rss feed url.
- colour – the colour of the border on the left side of the message. Can be useful to easily distinguish between different journals/sources/plans.
- thumb – nice option to add a thumbnail picture on the right
- max_len – the maximum length of an individual message in characters.
- max_msg – the maximum amount of messages to receive from this specific source.
You can create as many watch lists as you wish, one per plan, and place them inside the KeepingUpWithResearch/daily_watch/PaperWatchDog/files directory.
- [Optional] Create a “seen” log file and a “filter keys” txt file
Two available options that exist, but are not mandatory:- Caching the articles you’ve seen to avoid duplications . In cases where you might think an article can appear twice in the rss feed or if you are using the same source in different plans and want to avoid seeing the same article multiple times. Basically just create an empty log file, check out the explainability_seen.log example.
Note: it is important to empty the log file every once in a while to avoid memory abuse as well as slow run. I’ve done it using a short bash script (delete_log_files.sh) which I scheduled using crontab. - Filtering the rss feed based on keywords. The filtration is based on the name of the article only. Adding words that are preceded by ‘+’ means only articles that have this word (case insensitive) in their title will be posted. While adding words that have ‘-’ before them will cause articles with this word to be avoided. See example “explainability_filter_keys.txt”
If using these options make sure to place the file in the /files directory.
- Caching the articles you’ve seen to avoid duplications . In cases where you might think an article can appear twice in the rss feed or if you are using the same source in different plans and want to avoid seeing the same article multiple times. Basically just create an empty log file, check out the explainability_seen.log example.
- Create a short script to run your plan
This script will be used in crontab to schedule your run so one should be created for each plan. You can look at the example of KeepingUpWithResearch/run_explainability_rssfeed.sh

Change the path to run_rss_reader.py accordingly. Add your watch list yml file and your webhook that you established on step 1. Use the parameters -sf and -fkeys if you like to pass the seen log file and the filter keys file.
- Add your plan to crontab
Almost there! Now that you have created all the needed files and scripts, all that is left is to automatically schedule the task using crontab.
Note that you should consider the frequency of the plan based on the frequency the rss feed you are using is updated.
Crontab in general is a great tool for scheduling different tasks. Read more about the options and configurations here. To use crontab for our purpose:
In the command line, type `crontab -e` to enter the editing mode.
Add the following command (example shown for run_explainability_rssfeed):
`30 09 * * 0,1,2,3,4 bash -i /path/to/script/run_explainability_rssfeed.sh`
In this example the plan is running daily Sun-Thu on 09:30AM.
All Done! Now, your plan will run and post to the slack channel of your choice, with the frequency you configured.
And this is how it will look :

A few notes and tips:
- Make sure to limit the number of messages per source, otherwise you will be bombarded with posts. 10-30 per day is a good number.
- Currently the Paper.py module parses well rss feeds from all sub-archives of arxiv as well as Towards data science and a few other journals. Uniquely structured rss feeds might require some extra code manipulations to run well.
- If you have a few teams with different research interests consider making a few channels, each with its own plans.
- Use filtering keywords to “fish” the relevant papers. Get creative and don’t forget inflections of words (i.e explain, explanation etc..)
Periodical exploration of Connected Papers
While daily updates on what is new in the journals or websites of your choice is important to get a good sense of the innovation across the entire field, you might also want to follow the research on specific topics. This can be accomplished naively by following the new citations of the papers of interest, or by exploring the expansion of the graph created by Connected Papers based on the paper.
Connected papers (3) is a unique tool that presents a graph of papers based on the paper you input it, where the similarity metric that is used is co-citation and bibliographic coupling.
Exploring the graphs of your pillar papers is useful not just as a one time event but as a periodical recurring inspection. To achieve that we used a very similar solution to the daily rss feed – a periodical reminder post to a slack channel with the direct links to the graphs.
This way you both make it very easy for the user (one click + refresh away) and add a reminder.
Steps 1-3 are the same as above. The files to set up the plan are in the github repository in the KeepingUpWithResearch/connected_papers directory. All you need to do is to create a yml with the urls you want to post periodically. See the example KeepingUpWithResearch/connected_papers/files/urls_to_follow.yml
![]()
The entry name (Cause) has no effect and simply needs to be unique. The other fields are:
– name: the paper’s name
– author: the authors names
– url: the link to the graph created on Connected Graphs after inputting the paper
Then, create once again a bash script that runs the KeepingUpWithResearch/connected_papers/run_connected_papers_poster.py (see example KeepingUpWithResearch/run_connected_papers.sh) and create a crontab entry to schedule this task (see steps 6 and 7 above).
Following key players on Twitter
Scientists today are using social media in general and Twitter specifically to transfer their ideas and research faster, share knowledge and get feedback both from their fellow scientists as well as the general public (4). However, Twitter has over 300 million active users (5)(up. 2019), so we again must filter.
The way we achieved that in our team was by choosing a few power users that are related to our research field as well as very active on Twitter (“topic leaders”). We then opened a new slack channel that follows their tweets.
To post tweets on a slack channel you can use the Twitter app on slack.
Go to apps > add a new app and choose Twitter.
Then, in the app settings you can add this app multiple times to slack, each for each user you want to follow.
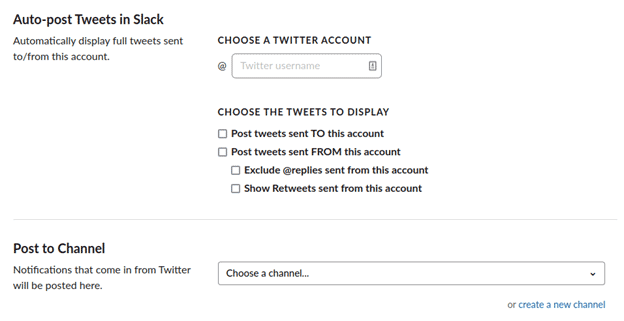
In “choose which tweets to display” you can refine your tracking.
In summary, to be relevant and up to date we need to follow the research and innovation in our area of interest. However, this can seem intimidating and almost impossible with today’s pace and flood of information. To deal with this, teams and individuals can harness the power of Slack, some python code and other tools. The solution has to be as easy and accessible as possible to make it sustainable. In this blog post I’ve tried to introduce you with some detailed solutions we adopted in our team, with hope that this can also be useful for others.
References:
- https://arxiv.org/help/stats/2020_by_area/index
- https://github.com/skojaku/paper-watch-dog
- https://www.connectedpapers.com/
- Darling, E. S., Shiffman, D., Côté, I. M., & Drew, J. A. (2013). The role of Twitter in the life cycle of a scientific publication. arXiv preprint arXiv:1305.0435.
- https://www.statista.com/statistics/282087/number-of-monthly-active-twitter-users/